
Ученые из Базельского и Невшательского университетов в Швейцарии в своем исследовании установили, что крупные языковые модели, основанные на искусственном интеллекте, все еще не способны эффективно воспроизводить поведение людей.
Лукас Биетти, один из авторов этого труда, подчеркнул, что LLM общаются иначе, чем люди. Специалисты провели тесты на моделях вроде ChatGPT-4, Claude Sonnet 3.5, Vicuna и Wayfarer.
В ходе эксперимента они сначала отдельно сравнили записи реальных телефонных бесед между людьми и их имитацию, созданную большими языковыми моделями. После этого исследователи проверили, насколько просто для людей различить настоящие телефонные диалоги от общения ИИ.
Данные эксперимента подтвердили, что большинство участников без труда распознавали отличия между разговорами людей и искусственного интеллекта. Как отмечают эксперты, в человеческом общении есть нюанс имитации, ведь мы постоянно корректируем слова в зависимости от собеседника, но этот нюанс обычно слишком незаметен, чтобы его сразу уловить. В отличие от этого, LLM проявляют чрезмерную склонность к копированию, и люди это четко ощущают. Такое явление специалисты называют чрезмерным выравниванием.
В кинолентах, где сценарий написан без должного внимания, диалоги часто звучат фальшиво. В подобных ситуациях авторы не стремятся к аутентичности, а ограничиваются только самыми необходимыми фразами.
В обыденных разговорах люди обычно активно используют короткие выражения, которые известны как дискурсивные маркеры. Среди них – слова вроде «да», «ну», «как бы» или «в любом случае». Эти элементы играют важную социальную роль, помогая показать интерес, единство мнений, эмоциональное отношение или значимость для партнера по беседе. Тем не менее, большие языковые модели пока не умеют правильно обращаться с такими словами, применяя их хаотично и часто неверно. Именно это позволяет людям легко их выявлять.
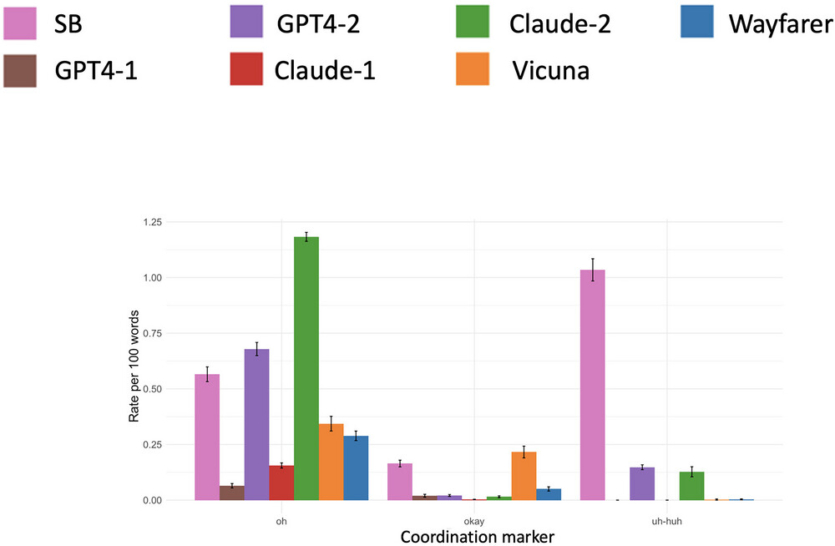
Перед тем, как затронуть основную тему, люди часто начинают с нейтральных фраз, например, «Привет», «Как дела» или «Приятно тебя видеть». Беседа может стартовать с чего-то несущественного, а потом постепенно перейти к главному вопросу. Такие естественные переходы до сих пор представляют трудность для LLM.
Похожие проблемы возникают и с окончанием диалога. Мы не прерываем разговор внезапно, как только передали нужную информацию. С этим аспектом большие языковые модели тоже справляются недостаточно хорошо.